In this blog post we’ll calculate the share of a row per group. There are multiple ways to do this: with aggregate functions and with analytic functions. We’ll go over both and demonstrate how analytic functions are far superior in terms of readability.
First, let’s create a table to demonstrate the ins and outs of PARTITION BY, which we will be referring to as iowa_liquor_by_vendor. Feel free to remove the ORDER BY clause.
WITH iowa_liquor_by_vendor AS (
SELECT
county,
city,
vendor_name,
CAST(SUM(sale_dollars) AS INT) sale_dollars
FROM
`bigquery-public-data.iowa_liquor_sales.sales`
WHERE
EXTRACT(YEAR FROM date) = 2017
AND county IS NOT NULL
GROUP BY
county, city, vendor_name
ORDER BY
county, city, vendor_name
)
...This will return a table that has aggregated sales by county, city, and vendor_name.
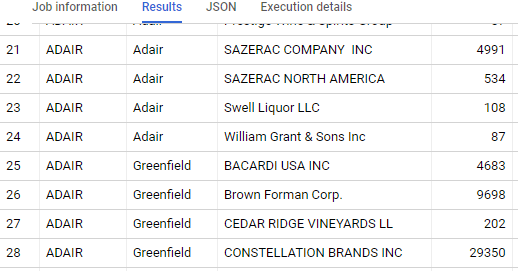
Calculate share per category using GROUP BY
Let’s assume you’re trying to create a report that wants to show the share of each vendor_name per city. With basic SQL clauses, you could come up with something like this. It creates an extra intermediate table, where all sales are aggregated per city. This aggregation can then be used in the denominator where the share is calculated.
...,
iowa_liquor_by_city AS (
SELECT
county,
city,
SUM(sale_dollars) as sale_dollars
FROM
iowa_liquor_by_vendor
GROUP BY
county, city
)
SELECT
v.county,
v.city,
v.vendor_name,
ROUND(SUM(c.sale_dollars)) city_sales,
ROUND(SUM(v.sale_dollars) / SUM(c.sale_dollars),2) city_vendor_share
FROM
iowa_liquor_by_vendor v
LEFT JOIN iowa_liquor_by_city c ON v.county = c.county AND v.city = c.city
GROUP BY
v.county,
v.city,
v.vendor_name
ORDER BY
v.county,
v.city,
v.vendor_nameCalculate share per category using PARTITION BY
The PARTITION BY clause is an essential component of BigQuery’s analytic functions. It allows the user to apply aggregate functions,… without aggregating. The number of rows stay the same, and the aggregated numbers that you would expect when using a GROUP BY clause, is instead applied on all the rows over which you aggregated.
Confused? Take a look at this example.
...
SELECT
county,
city,
vendor_name,
ROUND(SUM(sale_dollars) OVER (PARTITION BY county, city),2) city_sales,
ROUND(sale_dollars / SUM(sale_dollars) OVER (PARTITION BY county, city),2) city_vendor_share
FROM
iowa_liquor_by_vendor
ORDER BY
county,
city,
vendor_nameThis query is a lot shorter, yet produces the same result as the previous query. As you can see, in the fourth column the aggregate sales per city can be found. This is done by summing sales per partition of cities. In the final column, we use the same technique but use it as a denominator to calculate the share per city.
FYI: I had to partition over two columns in this example, because there are cities with the same name, but in different counties.
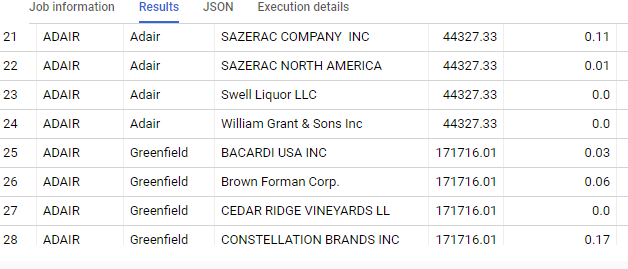
Analytic functions (also known as window functions) aren’t exclusive to BigQuery (e.g. SQL Server, Oracle, Postgres), but the syntax and scope isn’t identical. As you can see, they are really powerful and it doesn’t hurt to get to know them better.
This was really good and straight to the point. Just wanted to see what the equivalent GROUP BY would be in place of a PARTITION BY and I get it.
Thanks 🙂