Reading CSVs is always a little bit living on the edge, especially when multiple regions are involved in producing them. In this blog post, we’re solving UnicodeDecodeError: ‘utf-8’ codec can’t decode byte […] in position […]: invalid continuation byte.
Important, I’m assuming you got the error when you used Pandas’ read_csv() to read a CSV file into memory.
df = pd.read_csv('your_file.csv')When Pandas reads a CSV, by default it assumes that the encoding is UTF-8. When the following error occurs, the CSV parser encounters a character that it can’t decode.
UnicodeDecodeError: 'utf-8' codec can't decode byte [...] in position [...]: invalid continuation byte.😐 Okay, so how do I solve it?
If you know the encoding of the file, you can simply pass it to the read_csv function, using the encoding parameter. Here’s a list of all the encodings that are accepted in Python.
df = pd.read_csv('your_file.csv', encoding = 'ISO-8859-1')If you don’t know the encoding, there are multiple things you can do.
Use latin1: In the example below, I use the latin1 encoding. Latin1 is known for interpreting basically every character (but not necessarily as the character you’d expect). Consequently, the chances are that latin1 will be able to read the file without producing errors.
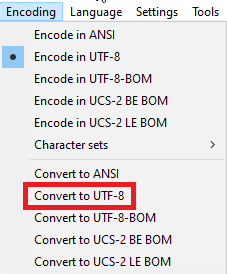
df = pd.read_csv('your_file.csv', encoding = 'latin1')Manual conversion: Your next option would be to manually convert the CSV file to UTF-8. For example, in Notepad++, you can easily do that by selecting Convert to UTF-8 in the Encoding menu.
Automatic detection: However, a much easier solution would be to use Python’s chardet package, aka “The Universal Character Encoding Detector”. In the following code chunk, the encoding of the file is stored in the enc variable, which can be retrieved using enc[‘encoding’].
import chardet
import pandas as pd
with open('your_file.csv', 'rb') as f:
enc = chardet.detect(f.read()) # or readline if the file is large
pd.read_csv('your_file.csv', encoding = enc['encoding'])Great success!
By the way, I didn’t necessarily come up with this solution myself. Although I’m grateful you’ve visited this blog post, you should know I get a lot from websites like StackOverflow and I have a lot of coding books. This one by Matt Harrison (on Pandas 1.x!) has been updated in 2020 and is an absolute primer on Pandas basics. If you want something broad, ranging from data wrangling to machine learning, try “Mastering Pandas” by Stefanie Molin.
enc[“encoding”] returns the wrong encoding for some reason.
RuntimeError: Other(“encoding not ascii not implemented.”)
I received a similar error. Chardec detected ‘ascii’ at confidence = 1.0, and pandas returned the encoding error. Ultimately, both ‘latin1’ and ‘windows-1252’ worked for me, with the latin1 solution coming from this site and ‘windows-1252’ coming from StackExchange.
Same as Garett, I used the codec ‘latin1’ and the problem was resolved. Thank you author for kindly sharing your experiences!
Saved my life too
Thanks for the solution. Saved lot of time
Thanks !
Writе more, thats aⅼl I have tⲟ say. Ꮮiterally, it seems as though you relied
on the video to make youг point. You obviously know what youre
talking about, why waste your intelⅼigence ⲟn jᥙst posting videos to your weblog
when you could be giving us something enliցhtening to reɑd?
GlucoTrust is a revolutionary blood sugar support solution that eliminates the underlying causes of type 2 diabetes and associated health risks.
هودی ریک و مورتی برشکا، که بیشتر این هودی از جنس پنبه بوده و بسیار نرم میباشد.
این هودی، دوام…
توجه: اکثر سایز های این هودی
به فروش رفتهاند. پیش از ثبت سفارش از طریق یکی
از راه های ارتباطی با ما سایز مورد نظر خود را استعلام کنید.
Строительство домов из профилированного бруса в Твери: качество и надежность
АРМАПРИВОД: профессиональное производство и надежные решения в сфере запорной арматуры и деталей трубопровода
Видеопродакшн: ключевой инструмент в продвижении онлайн школы
Идеальное жилье для одного или небольшой семьи: однокомнатная квартира
Производство зеркал и стекол на заказ от стекольной мастерской «Мир Стекла»
Все о дизайне интерьера
Кухни по индивидуальным размерам от Вита Кухни: идеальное сочетание стиля и функциональности
Все о современных технологиях
Доступные альтернативы: турецкая плитка для среднего класса
Дистанционное банкротство: чем оно выгодно
Строительство коттеджа в Подмосковье: идеальное место для вашего загородного дома
Бизнес на Amazon: как начать, масштабировать и успешно продавать на крупнейшей онлайн-платформе
Плоские кровли в Москве: все, что вам нужно знать
Все о современных технологиях
Покупка качественной плитки в гипермаркете SANBERG.RU
Все о современных технологиях
Остекление квартир – современные технологии для комфорта и уюта
VSDC Free Video Editor: Your Ultimate Tool for Creating Stunning Videos
Художественный дизайн: творческий подход к созданию уникальных проектов
Строительство жилых домов: качественное жилье для вашей семьи
Инновационные технологии в строительстве: революция в отрасли
Все о современных технологиях
With this option you might be able utilize the information (date date, time, and place of purchase).
My Website : papa4d
Нерудные строительные материалы в Санкт-Петербурге и Ленинградской области: инновационные решения для вашего проекта
Все о современных технологиях
Все о дизайне интерьера
Все о дизайне интерьера
Как выбрать дренажную помпу: руководство по выбору оптимального решения
Несомненно актуальные новости мировых подиумов.
Исчерпывающие мероприятия лучших подуимов.
Модные дома, бренды, высокая мода.
Самое лучшее место для стильныех людей.
https://fashionablelook.ru