Fundamental to data modeling is that you need a fact table or a table with a unique key per row. That is no different in GoodData. In this blog post, I tackle a specific error that you might run into if your dataset doesn’t meet the necessary requirements.
When I tried to publish my data source (BigQuery) into a logical data model (LDM), GoodData showed me the following error.

I highlighted a specific part of the error that is of relevance:
Target model is invalid.: [A dataset must have either a fact or an anchor with a label or a valid grain. Dataset […] does not contain any fact. Add an anchor with a label or a valid grain to dataset […] If the dataset has a Fact Table Grain, try to query the model with the parameter includeGrain=true (model/view?includeGrain=true)]: The request could not be understood by the server due to malformed syntax.
When you generate the output stage in the data integration console, you get a query (or multiple) that generates a view within your data warehouse. It’s this view that GoodData will use to load the data.
-- gd_view_event_stream_gooddata -- -------------------------------------------------- CREATE OR REPLACE VIEW <dataset>.gd_view_event_stream_gooddata AS SELECT browser AS a__browser, browserLanguage AS a__browserlanguage, browserVersion AS a__browserversion, deviceCategory AS a__devicecategory, [...] FROM <project>.<dataset>.view_event_stream_gooddata;
You might have noticed that in the query, GoodData creates a prefix for every column name. These prefixes indicate that the column is of a certain type. The prefixes that we need to create a valid data source is either cp__ or f__. If that’s not the case, you’re gonna have to make modifications to the view.
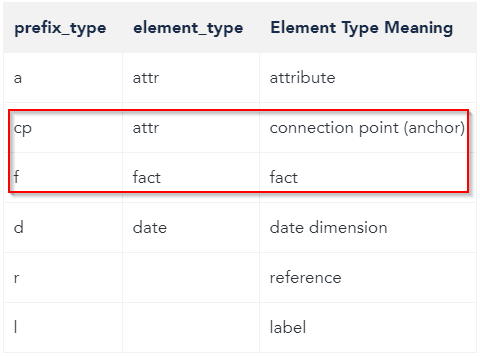
Solution one: create facts
The first (rather suboptimal) solution is to create a fact. If there’s no real “fact” in your data, for example when every row is a hit or an event, you can simply add a column of 1’s to your table. Like this:
1 as f__hitcount
Now, GoodData will no longer produce an error when you create a logical data model (LDM).
Solution Two: Create anchors
A more correct way is to generate a unique key for every row. Instead of counting the facts, GoodData’s visualizations will count unique anchors. You can achieve this by adding a cp__ (connection point) column to the view. Many SQL syntaxes have a function to generate such a key — and so do BigQuery and Snowflake.
GENERATE_UUID() as cp__id -- Google BigQuery UUID_STRING() as cp__id -- Snowflake
If you want to generate a UUID in RedShift, follow this tutorial.
Now, you can start analyzing your data in GoodData.
Your article helped me a lot, is there any more related content? Thanks!