Because there are (too) many ways to cast a Pandas DataFrame from long to wide format, I decided to list four ways to achieve that goal. The four functions I describe in this article are the following.
| Function | Object | aggregation | Can handle NaNs |
|---|---|---|---|
| pivot | DataFrame | no | no |
| pivot_table | DataFrame | yes | yes |
| unstack | DataFrame with MultiIndex rows | no | no |
| crosstab | Series/Arrays | yes | no |
First, let’s create some dummy data. It’s a simple 5 row data frame that describes the color, taste and calories of fruit.
import random
import pandas as pd
import numpy as np
fruits = ['apple','apple', 'pear','pear','plum']
colors = ['green','green','red','yellow','red']
tastes = ['sour','bitter','sweet','sour', 'sweet']
calories = np.round(np.random.normal(50,10,5), decimals = 0)
df = pd.DataFrame({'fruit': fruits,
'color': colors,
'taste': tastes,
'calories': calories})
df.head()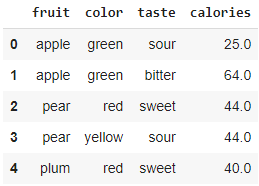
Pivot
The pivot function reshapes DataFrames by casting a the values of a column to a number of columns, based on the number of unique values within that column.
df.pivot(index = 'fruit', columns = 'taste', values = 'calories')
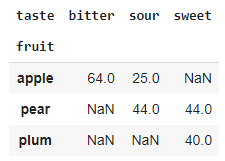
To use the pivot function, it is required that all column/index combinations are unique.
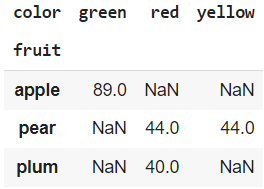
df.pivot(index = 'fruit', columns = 'color', values = 'calories')
This example will produce the following error, because the combination of fruit/color produces a duplicate row, because when using pivot, the values aren’t aggregated.
ValueError: Index contains duplicate entries, cannot reshape
🙋♀️ Here’s an overview of what you should remember about pivot():
- A function with limited features to reshape DataFrames from long to wide format
- Requires a unique index/column combination
- Does not aggregate values
- Might produce NaNs, doesn’t have a parameter to handle them
Pivot_table
Just like pivot(), the pivot_table function reshapes DataFrames by casting them from long to wide.
df.pivot_table(index = 'fruit', columns = 'color', values = 'calories', \
aggfunc = 'sum', fill_value = 0)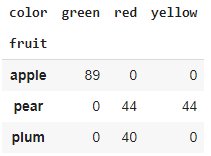
Unlike pivot(), it can aggregate numeric columns using the aggfunc parameter, so it does not need unique row/column combinations. Of course, it can still produce row/column combinations that are empty, but these can be filled using the fill_value parameter.
🙋♀️ Here’s an overview of what you should remember about pivot_table():
- A function to reshape DataFrames from long to wide format
- Can aggregate values
- Can handle NaNs by filling it with a value of your choice
Unstack
The unstack function, is a fast and convenient way to cast a MultiIndex DataFrame from wide to long format. It will pivot the values of the index with the highest level. You’ll end up with a DataFrame with MultiIndex columns. Consequently, if your goal is to end up with a normal DataFrame, you’ll have to flatten it afterwards.
df[['fruit', 'taste', 'calories']].set_index(['fruit','taste']).unstack()
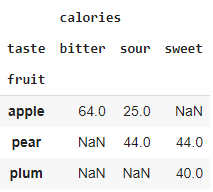
💥 Keep in mind, just like pivot(), the unstack function requires unique row/column combinations. If you don’t respect this, you’ll end up with the error “ValueError: Index contains duplicate entries, cannot reshape”.
🙋♀️ Here’s an overview of what you should remember about unstack():
- A function to quickly pivot the index with the highest level to columns.
- Can not aggregate values.
- Can’t handle NaNs.
Crosstab
Another way to pivot your table from long to wide format, is using the crosstab function. It’s not necessarily designed for data transformation, but it is a great tool for presenting data in a comprehensible way. Hence the name ‘crosstab’.
pd.crosstab(index = df.fruit, columns = df.taste, values = df.calories, aggfunc = 'sum' )
Important to know is that if you set the values parameter, you also need to specify an aggfunc. Otherwise, you’ll run into the following error:
ValueError: values cannot be used without an aggfunc.
🙋♀️ Here’s an overview of what you should remember about crosstab():
- Turn series or arrays into a DataFrame in wide format.
- Requires agrgegating values.
- Cannot handle NaNs.
By the way, I didn’t necessarily come up with this solution myself. Although I’m grateful you’ve visited this blog post, you should know I get a lot from websites like StackOverflow and I have a lot of coding books. This one by Matt Harrison (on Pandas 1.x!) has been updated in 2020 and is an absolute primer on Pandas basics. If you want something broad, ranging from data wrangling to machine learning, try “Mastering Pandas” by Stefanie Molin.