In this blog post I elaborate on the reality that statistical models often obscure the fact that some problems can actually be solved in a way that requires less time, resources and headaches. By using reference models and heuristics, decision makers can evaluate if those seemingly brilliant consultants are solving problems or selling bullsh*t.
Do we need models?
Why do we build models? What is the value that we can create from them? In their book “An Introduction to Statistical Learning“, James, Witten, Hastie and Tibshirani outline two reasons.
The first is prediction: from a set of inputs X, we try to obtain the output Y. If we want to predict when we will arrive at an appointment (Y), we build a mental model where we input (X) our current location, our destination, our means of transportation and the estimated traffic at this time of the day. When you’re browsing Facebook, you’ll probably see ads which are tailor-made for you (Y), based on your previous behavior (X) on and outside of the social network. When a Tesla is driving in autopilot, it is scanning the environment (X) to choose what it should do next (Y).
The second is inference: from the data we want to understand the relationship between the input X and the output Y. We want answers to questions such as “is the relationship between X and Y linear?” and “which elements of our input X are associated with the output Y?”
It shouldn’t come as a surprise that very complicated models aren’t very handy for inference. However, they might be very good at prediction. In other words, there is a trade-off between accuracy and interpretability. In an effort to have both, there is a whole research field known as Explainable Artificial Intelligence or XAI. I always think of models as abstractions of the real world and based on your goals, they will be more or less abstract.
Models are truly everywhere. Let’s say you work in retail. Your store manager wants to predict the most busy hours, so he can plan working hours for his staff accordingly. The marketing will want to predict what to advertise to which people. By predicting sales, the operations team will want to allocate the right amounts of goods to the appropriate stores. And by inferring the relationship between demand and supply, the pricing team will set prices that maximize profit.
How do we know that they are any good?
Sometimes, there are multiple models that try to achieve the same goal. In formal settings, we have tools and tests that can help us select the model that is best in line with our goals. For example, the F-statistic is a great tool to evaluate the performance of a linear regression model. It’s great because it accounts for degrees of freedom. Broadly speaking, it lives up to Occam’s Razor: it punishes models that are unnecessarily complicated. However, the world isn’t a formal setting: enter heuristics.
Heuristics are mental shortcuts, often based on past experience. In a way, they are the simplest of models. Far too many times have I come across models that appear to be amazing products of data science, but can’t even beat a simple heuristic. Let’s start with this one.
Exhibit A: In her blog post about time series and long short-term memory models, data science blogger Susan Li concludes that “LSTMs are amazing”: just look at this chart.
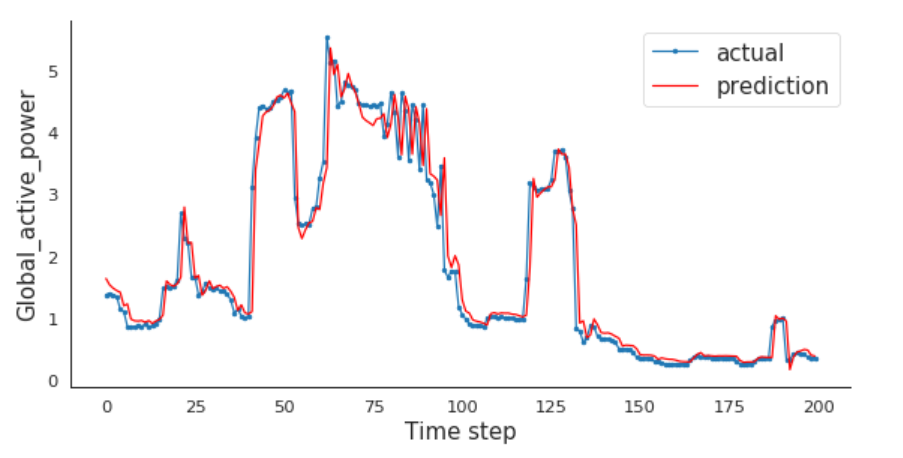
Even though the model appears to be spot-on, the predictions actually suck. Let me explain it with an example of my own.
Exhibit B: Recently, in an exercise to try to predict occupancy rates in a hospital, I built an LSTM model that appeared to perform fairly well when making predictions for t at t-1 — in layman’s terms: predicting for tomorrow. However, visual inspection was certainly not enough to evaluate the model I had created. The goal was to optimize staffing, to make the job of the planner easier or to do better than him or her. So I compared my model to a heuristic: what if I predict that the occupancy rate tomorrow was the same as today? My model must outperform this silly heuristic, right? Well, no, not at all. And it is the same with Susan Li’s model: if you carefully inspect the prediction line, you will see that it looks like a calendar, running one day late, but then even a little bit worse.

Exhibit C. Some months ago, a company I worked for ordered a model at a rival consulting company that could predict the return-on-investment for all their media spent — a market mix model. I strongly advised against it because I was very skeptical of the potential returns. Although the final product definitely required some data science craftsmanship, it couldn’t beat common sense and, to me, was very underwhelming.
Exhibit D. Belgian consultancy firm Kohera advertised on their blog that they correctly predicted three songs from the top 10 in a very popular music chart known as “De Tijdloze” (the timeless) using an ARIMA model. My bullshit radar went haywire: three out of ten doesn’t seem that hard, knowing that the top ten barely changes.

So I programmed a Monte Carlo simulation. What if I pick 9 or 10 (they predicted 9 out of 10 songs in the top ten) numbers from the top ten in 2018 and randomly assign them a spot in the top ten of 2019? Well, by doing so, I had a 6% to 8% probability to get the same accuracy or better. This means their model is not even statistically significant (by traditional standards) from a random selection. I also compared to a heuristic, what if the position of the songs in the top ten in 2018 stayed the same in 2019? How many would I predict correctly? Well… three, like their ARIMA-model.
It’s not that they did a bad job. It’s just that, starting from their chartist approach, there doesn’t appear to be much of a pattern in the data that can be used to predict the future. A nice marketing gimmick, but not really newsworthy.
Compare to simple models and ask hard questions
You don’t evaluate a baseball player’s batting statistics just by looking at it, you compare it to other players’ stats. The same goes for players and their performance in any sport. The same goes for models. Difficult words and scientism often obscure the fact that a problem was solved in an unnecessarily hard way. Someone can brag about complicated models, but if they don’t beat a simple reference model or heuristic, they are completely useless.
Data science often is an iterative process with no predetermined outcome. Afraid of the backlash, data scientists can obscure the fact that they couldn’t find a lot of signal in the noise, while in fact, they should be honest about the products they create. My advice to decision makers: if a consultant or employee proposes you a model that doesn’t beat your experience or common sense, start asking the hard questions.