
Reading CSVs is always a little bit living on the edge, especially when multiple regions are involved in producing them. In this blog post, we’re solving UnicodeDecodeError: ‘utf-8’ codec can’t decode byte […] in position […]: invalid continuation byte.
Important, I’m assuming you got the error when you used Pandas’ read_csv() to read a CSV file into memory.
df = pd.read_csv('your_file.csv')When Pandas reads a CSV, by default it assumes that the encoding is UTF-8. When the following error occurs, the CSV parser encounters a character that it can’t decode.
UnicodeDecodeError: 'utf-8' codec can't decode byte [...] in position [...]: invalid continuation byte.😐 Okay, so how do I solve it?
If you know the encoding of the file, you can simply pass it to the read_csv function, using the encoding parameter. Here’s a list of all the encodings that are accepted in Python.
df = pd.read_csv('your_file.csv', encoding = 'ISO-8859-1')If you don’t know the encoding, there are multiple things you can do.
Use latin1: In the example below, I use the latin1 encoding. Latin1 is known for interpreting basically every character (but not necessarily as the character you’d expect). Consequently, the chances are that latin1 will be able to read the file without producing errors.
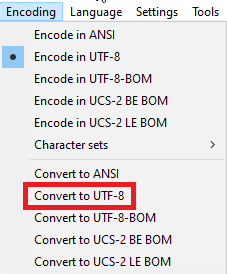
df = pd.read_csv('your_file.csv', encoding = 'latin1')Manual conversion: Your next option would be to manually convert the CSV file to UTF-8. For example, in Notepad++, you can easily do that by selecting Convert to UTF-8 in the Encoding menu.

Automatic detection: However, a much easier solution would be to use Python’s chardet package, aka “The Universal Character Encoding Detector”. In the following code chunk, the encoding of the file is stored in the enc variable, which can be retrieved using enc[‘encoding’].
import chardet
import pandas as pd
with open('your_file.csv', 'rb') as f:
enc = chardet.detect(f.read()) # or readline if the file is large
pd.read_csv('your_file.csv', encoding = enc['encoding'])Great success!
By the way, I didn’t necessarily come up with this solution myself. Although I’m grateful you’ve visited this blog post, you should know I get a lot from websites like StackOverflow and I have a lot of coding books. This one by Matt Harrison (on Pandas 1.x!) has been updated in 2020 and is an absolute primer on Pandas basics. If you want something broad, ranging from data wrangling to machine learning, try “Mastering Pandas” by Stefanie Molin.